Provenance-Based Debugging
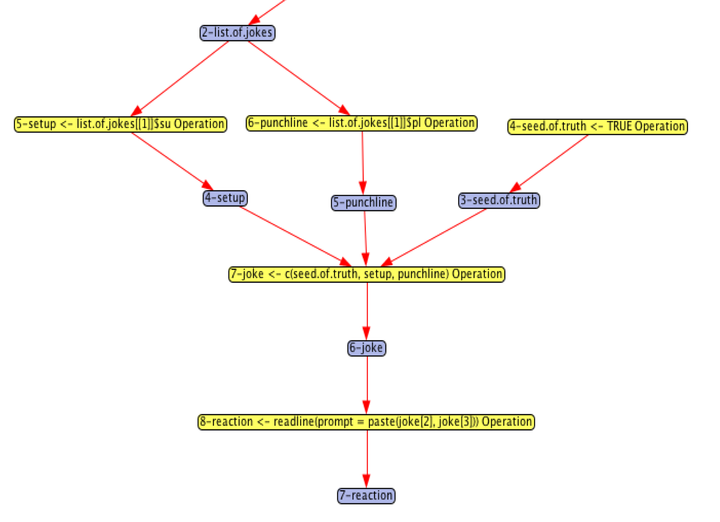
Overview
I have worked on two provenance based-debuggers, provDebugR and provdb.
ProvDebugR
My research group and I at Harvard Forest designed provDebugR to target the R language. This debugger uses language-level provenance generated by RDataTracker as its input, and provides many normal debugger features, as well as additional features such as lineage-tracking and backwards debugging. ProvDebugR is currently available on CRAN for any scientists who use R to download and use. While provDebugR targets scientists using R for analysis, developers who want to build tools on top of R language-level provenance can also make use of the provParseR ( CRAN Link) package. This R package takes language-level provenance as an input, either from a JSON file or directly from RDataTracker, and converts it into a more R-friendly form.
provdb
This debugger is an (optimistically) language-agnostic version of provDebugR. It targets the same language-level provenance format, but works for any language so long as a tool can produce the provenance in the same prov-json that RDataTracker uses. At the moment this means it is mostly a version of provDebugR written in Python, although researchers have been working on a tool to convert provenance generated by noWorkflow into RDataTracker’s prov-json. In fact, I tested provdb on R provenance and Python provenance generated from a preliminary tool designed to convert noWorkflow provenance. This project served as my undergraduate capstone project for computer science at Carthage College. This package also contains a Python tool that is the equivalent of provParseR but generates Python’s pandas dataframes rather than native R dataframes. Developers wishing to create tools based on language-level provenance without writing R code can use this tool as well.